Random Forest Regression
Random Forest Regression is based on Decision Tree Regression. It will build ‘n_estimators’ of Decision Tree Regression, and using the average each decision tree predict value to improve the accuracy value, and control over-fitting.
More Info Using Scikit-Learn Built-in library: Scikit-Learn Random Forest Regression
n_estimators : integer, optional (default=10)
The number of trees in the forest.sample_ratio: percentage of total size
For some big dataset, it may take long time to build for random forest, therefore we can take some sample of the data to same time for build the random forest.
Methods
fit(self, X: pd.DataFrame, y: np.array)
Build a forest of trees from the training set (X, y).predict(self, X: pd.DataFrame)
Predict regression target for X.score(self, X: pd.DataFrame, y: np.array)
Returns the coefficient of determination $R^2$ of the prediction.
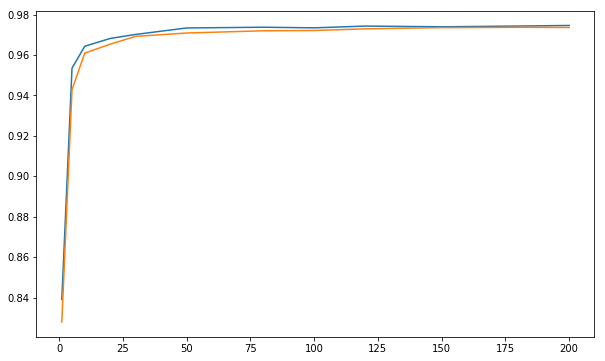
Graphic Example
- X-axis: Number of Random Forest estimators
- y-axis: The accuracy for predict values.
1 | import pandas as pd |
2019-04-14