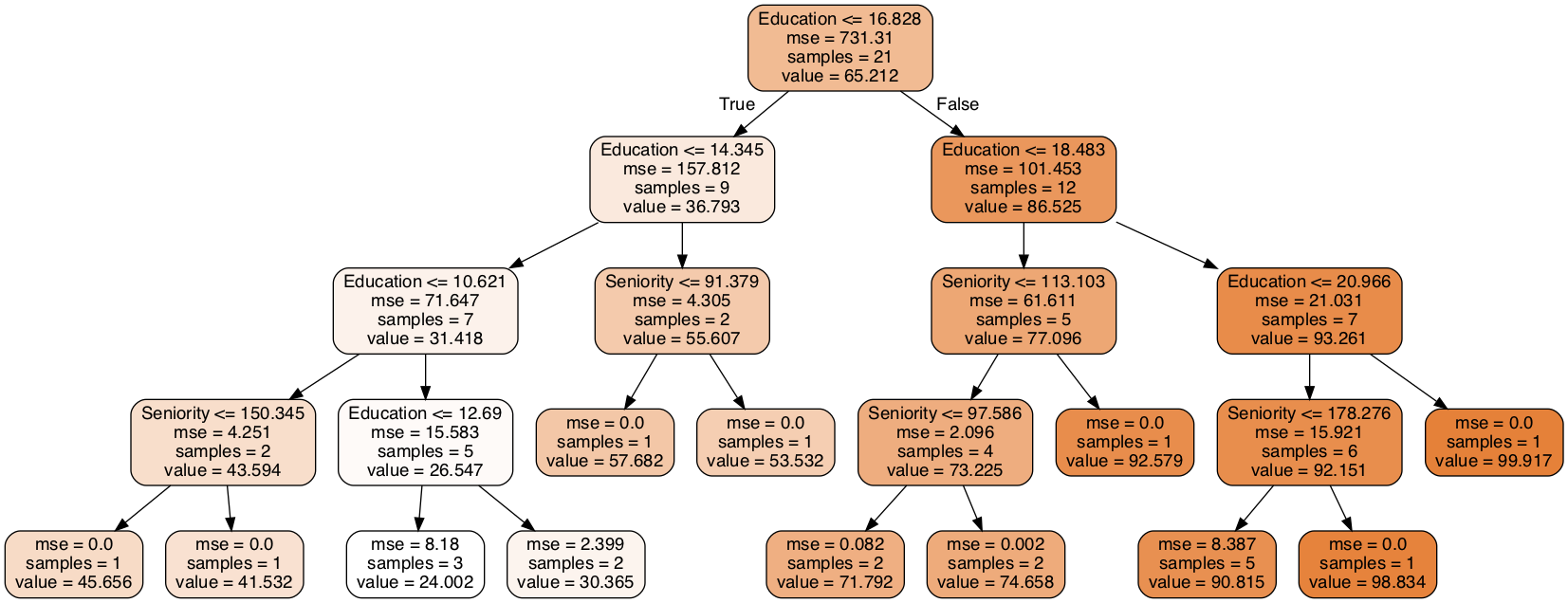
Decision Tree Regression
Using features data from DataFrame to train a regression tree model. The way to find the best split value is to find the best MSE in each feature type. When we found the BEST MSE value, the model will set it as the split value for current level. Separate the X and y into left subtree and right subtree, and keep going to train the model tree from subtree.
More Info Using Scikit-Learn Built-in library: Scikit-Learn Decision Tree Regression
max_depth: int or None, optional (default=None)
The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.min_samples_leaf: int, float, optional (default=1)
The minimum number of samples required to be at a leaf node.
Methods
fit(self, X: pd.DataFrame, y: np.array)
Build a decision tree regressor from the training set (X, y).predict(self, X: pd.DataFrame)
Predict regression value for X.score(self, X: pd.DataFrame, y: np.array)
Returns the coefficient of determination $R^2$ of the prediction.
Graphic Example
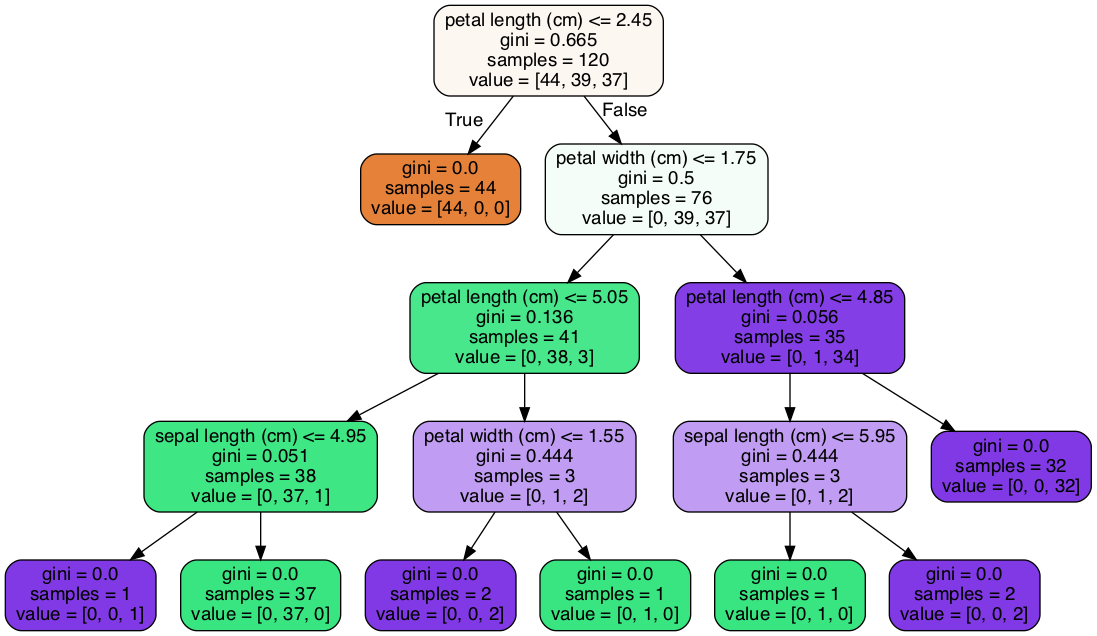
Decision Tree Classification
Using features data from DataFrame to train a regression tree model. The way to find the best split value is to find the best average subtree of GINI Impurity X Data Weight in each feature type. When we found the BEST (GINI Impurity X Data Weight) value, the model will set it as the split value for current level. Separate the X and y into left subtree and right subtree, and keep going to train the model tree from subtree.
More Info Using Scikit-Learn Built-in library. Scikit-Learn Decision Tree Regression
- GINI Impurity:
$$ GINI =1-\sum_{i=1}^{N}{p_{i}}^{2} $$
1 | def calc_gini(y, valueType): |
- Data Weight:
$$ Data Weight = {\sum_{i=1}^{N}{SubtreeNode}\over{TotalNode}} $$
1 | if left.any() and right.any(): |
max_depth: int or None, optional (default=None)
The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.min_samples_leaf: int, float, optional (default=1)
The minimum number of samples required to be at a leaf node.
Methods
fit(self, X: pd.DataFrame, y: np.array)
Build a decision tree classifier from the training set (X, y).predict(self, X: pd.DataFrame)
Predict class value for X.score(self, X: pd.DataFrame, y: np.array)
Returns the mean accuracy on the given test data and labels.
Graphic Example
2019-04-06